




‘Cloud Architecture’ สถาปัตยกรรมแห่งอนาคต เพื่อการยกระดับ IT Platform ให้ยืดหยุ่นกว่าที่เคย-รองรับการใช้งานระบบใหม่ได้ดีกว่าที่คิด
เมื่อระบบ Cloud Computing กำลังเป็นเทรนด์ใหม่ที่หลายฝ่ายคาดว่าจะเข้ามาเปลี่ยนแปลงการทำธุรกิจ เป็นโซลูชันให้กับงานระบบไอที ตั้งแต่การลดเวลาและขั้นตอนในการขยายเซิร์ฟเวอร์ (Server) ให้สามารถรองรับระบบใหม่ๆ ที่เพิ่มเติมเข้ามา ในขณะเดียวกันก็ช่วยลดภาระค่าใช้จ่ายที่ไม่จำเป็น และตอบโจทย์ความต้องการของทุกขนาดองค์กร แต่การใช้งานระบบคลาวน์ได้อย่างเหมาะสมและเต็มประสิทธิภาพสามารถรองรับการเติบโตในอนาคตได้ จำเป็นต้องมี ‘การออกแบบ Cloud Architecture’ เพื่อดึงศักยภาพในการใช้งานตามต้องการของภาคธุรกิจและสอดรับกับสถานการณ์ที่แต่ละองค์กรต้องรับมือ
ซึ่งการออกแบบ ‘Cloud Architecture’ ให้เหมาะสมกับแต่ละองค์กรนั้น จำเป็นต้องมีการศึกษาอย่างละเอียด ตั้งแต่ การศึกษาว่าระบบคลาวน์นั้นแตกต่างจากโครงสร้างระบบเดิมขององค์กรที่มีการดูแลอุปกรณ์เอง (On-premises) ศึกษาแนวทางในการเชื่อมต่อระบบคลาวน์กับระบบเดิมที่มีอยู่ ศึกษาความต้องการใช้งานขององค์กร ศึกษาการออกแบบความปลอดภัย และศึกษาการประเมินค่าใช้จ่ายอย่างรัดกุม รวมถึงศึกษาข้อควรระวังหรือปัญหาที่อาจเกิดขึ้นระหว่างการใช้งาน
วันนี้ ‘บลูบิค’ จึงนำเสนอข้อมูลเชิงลึกที่จะพาทุกคนไปรู้จัก ‘Cloud Architecture’ และ เหตุผลดีๆ ว่า ‘ทำไมภาคธุรกิจควรเริ่มให้ความสำคัญกับสถาปัตยกรรมแห่งอนาคต’ นี้
‘Cloud Architecture’ คืออะไร?
โดยพื้นฐานของระบบ ‘Cloud Architecture’ นั้น ไม่ต่างจากระบบ On-premises Infrastructure[1] เพียงแต่อุปกรณ์หรือเครื่อง Server นั้นอยู่ภายในศูนย์ข้อมูล (Data Center) ของผู้ให้บริการเท่านั้น ซึ่งผู้ใช้งานสามารถเข้าใช้งานผ่านระบบต่างๆ เช่น ผ่านหน้าเว็บไซต์ (Portal) ผ่านด้วยคำสั่ง Command-line interface[2] (CLI) โดยเน้นให้ผู้ใช้งานสามารถเข้าถึงบริการและระบบต่างๆ ได้อย่างสะดวกสบาย เพียงแค่เลือกและตั้งค่าจากนั้นระบบจะบริหารจัดการให้เอง หากไม่ต้องการใช้งานก็ทำการลบออก
ในส่วนของการเชื่อมต่อด้านโครงข่ายเน็ตเวิร์ค (Network) ทำได้เหมือนกับระบบที่อยู่บน On-Premises รวมไปถึงด้านความปลอดภัย (Security) ก็สามารถใช้งานร่วมกันได้ทั้งจากเครื่องมือที่ใช้งานอยู่บน On-premise และบน Cloud ซึ่งการนำเครื่องมือที่เป็นบริการบนคลาวน์มาใช้งานร่วมกับ On-premises นั้น เป็นไปตามมาตรฐานที่ทั่วโลกกำหนดเอาไว้ เช่นของผู้ให้บริการ Azure[3] หรือของผู้ให้บริการ AWS[4] จึงมั่นใจได้ว่าด้วยโครงสร้างและการพัฒนาระบบของผู้ให้บริการนั้นปลอดภัย
ความแตกต่างของทั้งสองระบบที่ชัดเจน คือ ค่าใช้จ่ายในการใช้งานและความรับผิดชอบในการส่วนงานต่างๆ หากเป็นระบบ On-premises เครื่องเซิร์ฟเวอร์นั้นจะต้องทำการสั่งซื้อล่วงหน้าและติดตั้งเอง ดังนั้นจะต้องมีการประเมินค่าใช้จ่ายล่วงหน้าไว้และอาจจะต้องชำระเต็มจำนวนทันทีที่สั่งซื้อ ในขณะที่การใช้งานระบบคลาวน์ ที่มีวิธีการคิดค่าใช้จ่ายแบบรายชั่วโมง (On-demand)[5] และชำระเป็นรายเดือน หรือใช้วิธีจองใช้งานระยะยาว 1 ปีหรือ 3 ปีและชำระแบบใช้ก่อน จ่ายทีหลัง นอกจากนี้ยังสามารถยกเลิกการใช้งานได้ตลอดเวลา โดยในส่วนการดูแลรักษาระบบจะแบ่งการรับผิดชอบกันระหว่างผู้ใช้งานและผู้ให้บริการ
รู้หรือไม่ ‘Cloud Architecture’ ทำงานอย่างไร?
นอกจากการให้บริการพื้นฐาน อย่างการใช้งานเครื่อง Server แล้ว ผู้ให้บริการคลาวน์ หลายรายมีการพัฒนาแอปพลิเคชัน (Application) และแพลตฟอร์มเพิ่มเติม เพื่อเพิ่มความสามารถในการพัฒนา Solutions และทำให้ใช้งานง่ายและตอบโจทย์มากขึ้น เช่น การใช้งาน Database โดยผู้ใช้งานไม่ต้องแบกรับภาระการดูแลรักษาอุปกรณ์เครื่องมือ รวมไปถึงการติดตั้งและการกำหนดการตั้งค่าพื้นฐานอีกด้วย เนื่องจากระบบจะจัดการให้โดยอัตโนมัติ ซึ่งผู้ใช้งานแค่นำการเชื่อมต่อ (Connection string) ก็สามารถเข้าถึงระบบฐานข้อมูลได้ทันที ซึ่งการใช้งานในรูปแบบนี้จะแบ่งหน้าที่ความรับผิดชอบออกเป็น 3 รูปแบบ ดังนี้
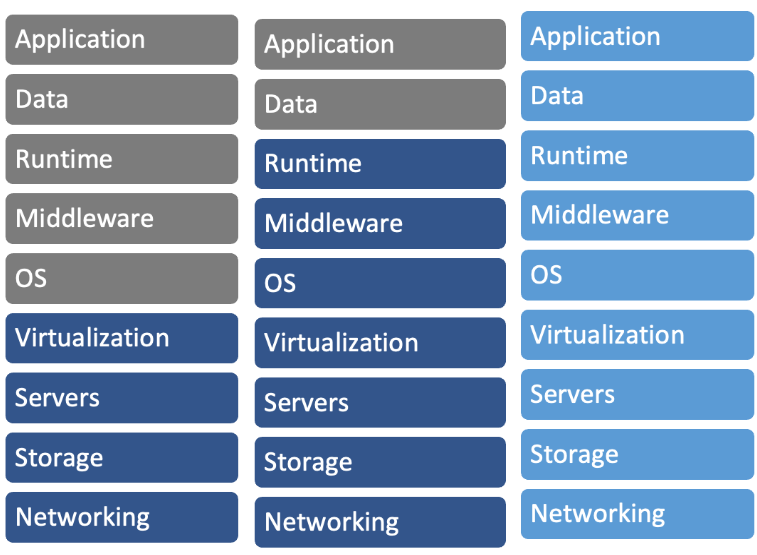
1. การให้บริการในรูปแบบของการให้ใช้งานโครงสร้างของระบบ หรือที่เรียกว่า Infrastructure as a Service (IaaS)[6] เช่นการใช้งานเครื่องมือ Server หรือ Virtual Machine โดยบริการในรูปแบบนี้ผู้ให้บริการจะรับผิดชอบในส่วนของ Network และ Storage และ Servers และ Virtualization ซึ่งผู้ใช้บริการจะรับผิดชอบในส่วนของ Operating system เป็นต้น ยกตัวอย่างเช่น การเลือก Windows หรือ Linux การทำ Security patching และการติดตั้ง Application เพิ่มเติม
2. การให้บริการในรูปแบบของการให้ใช้งานระบบเพลตฟอร์ม (Platform) หรือที่เรียกว่า Platform as a Service (IaaS)[7] เช่น การใช้งานระบบของ MapReduce[8] หรือที่รู้จักในการชื่อของ Hortonworks หรือ Cloudera ในโครงการที่เกี่ยวกับ Big Data Platform หรือการใช้งาน Kubernetes สำหรับการใช้งานร่วมกับ Container[9] ในโครงการของ Application โดยบริการในรูปแบบนี้ผู้ให้บริการจะรับผิดชอบในการบริหารจัดการอุปกรณ์ไปจนถึงระบบที่ทำการติดตั้งไว้ให้ โดยจะรวมไปถึงการปรับปรุง (Update) และการทำ Security patching ซึ่งผู้ใช้บริการจะมีความรับผิดชอบในการนำ Application ไปใช้งานบน Platform นั้น ๆ
3. การให้บริการในรูปแบบของการให้ใช้งานโปรแกรม หรือที่เรียกว่า Software as a Service (SaaS)[10] เช่น การใช้งานด้าน Monitoring และ Serverless[11] ซึ่งบริการนี้ระบบทั้งหมดผู้ให้บริการจะเป็นผู้รับผิดชอบเองทั้งหมด ผู้ให้บริการเพียงแค่ใส่ข้อมูลเข้าไปตามต้องการและนำผลลัพธ์ไปใช้งานต่อได้ทันที โดยระบบนี้มักจะเป็นระบบ Monitoring การทำงานหรือการใช้งานบนคลาวน์ หรือเป็นโปรแกรมที่ให้ผู้ใช้งานนำ Code ของตัวเองมาสั่งใช้งาน (Run) บนบริการและให้ผลลัพธิ์ตามต้องการ
จากรูปแบบการใช้งานบริการบนระบบคลาวน์นั้น หากจะพูดให้เข้าใจง่ายขึ้นก็คือ การใช้งาน ‘ระบบคลาวน์’ นั้น ควรให้ความสำคัญกับการออกแบบและการตั้งค่าการใช้งานต่าง ๆ ตามความต้องการใช้งานของแต่ละองค์กรมากกว่าการดูแลรักษาระบบที่ไม่จำเป็นและอาจจะเพิ่มภาระให้กับทางผู้ดูแลระบบมากเกินไป
เมื่อความปลอดภัยเป็นเรื่องสำคัญ
แล้ว ‘Cloud Architecture’ เชื่อถือได้แค่ไหนกัน?
โดยพื้นฐานแล้ว ระบบของคลาวน์ที่จะมีการออกแบบให้มีเครื่อง Server อยู่ในหลายพื้นที่ทั่วโลกหรือที่เรียกว่า Region และในแต่ละ Region นั้นจะมี Data Center หลายที่ หรือที่รียกว่า Availability Zone (AZ)[12] ซึ่งการใช้งานนั้นสามารถออกแบบให้มีการกระจายการใช้งานไปหลาย ๆ แหล่งเพื่อป้องกันระบบล่มและสามารถทำงานได้อยู่ตลอด ซึ่งการออกแบบนั้นนอกจากการทำการคัดลอกข้อมูลเก็บไว้หลายแหล่งแล้ว (Data Redundancy) ระบบยังสามารถออกแบบในระบบของ Infrastructure ได้ทั้ง 3 รูปแบบ

1. การออกแบบในรูปแบบของ High availability (HA)[13] เป็นการทำสำรอง Backup และกู้คืนระบบ Restore จากการทำ Snapshot การตั้งค่าและข้อมูลต่าง ๆ เอาไว้ เมื่อระบบเกิดปัญหา ก็จะนำ Snapshot ที่จัดเก็บไว้มาทำการ Restore เพื่อให้ระบบกลับมาใช้งานได้ต่อ โดยการจัดเก็บ Snapshot นี้ ผู้ให้บริการจะทำการสำรองเอาไว้หลายแหล่ง เพื่อให้มั่นใจได้ว่าข้อมูลจะไม่สูญหายไป เปรียบได้เหมือนการพกล้ออะไหล่เอาไว้ เผื่อต้องมีการเปลี่ยนหากยางแตก
2. การออกแบบในรูปแบบของ Fault Tolerant (FT)[14] เป็นการติดตั้งระบบให้ทำงานร่วมกันหลายเครื่องพร้อมกัน หากมีอุปกรณ์หรือเครื่อง Server ไหนเกิดข้อผิดพลาดหรือล่มไป ระบบทั้งหมดจะยังคงทำงานได้ตามปกติ เพียงแต่อาจจะส่งผลต่อการใช้งานบ้าง เช่น การใช้งานเครื่องมือหลายเครื่องบน Region เดียวกันแต่มีการกระจายการติดตั้งไปยัง Availability Zone ที่ต่างกัน เปรียบได้กับใบพัดของเครื่องบินที่หากมีเครื่องยนต์บางอันหยุดทำงานกลางอากาศแต่เครื่องยังคงบินต่อและร่อนลงได้อย่างปลอดภัย
3. การออกแบบในรูปแบบของ Disaster Recovery (DR)[15] เป็นการทำระบบสำรองเอาไว้ทั้งระบบอีกที่หนึ่ง โดยสามารถเปลี่ยนระบบหลักไปใช้งานได้ทันที เช่น การทำระบบทั้งระบบเอาไว้ที่เหมือนกันไม่ใช่เพียงแค่บางเครื่องมือโดยสำรองไว้ที่ต่าง Region อย่างการใช้งานในประเทศสิงคโปร์เป็นระบบหลัก แต่มีระบบสำรองเอาไว้ที่ประเทศฮ่องกง เปรียบเสมือนนักบินที่เป็นหัวใจหลักในการขับเครื่องบิน และสามารถดีดตัวเองออกมาเมื่อเครื่องบินไม่สามารถบินต่อได้ เพื่อให้นักบินสามารถไปขึ้นอีกลำเพื่อทำภาระกิจต่อไปได้
วางแผนการออกแบบ ‘Cloud Architecture’
อย่างไร…ให้งานไม่สะดุด
เนื่องจากระบบคลาวน์ยังเป็นสิ่งใหม่ ดังนั้น การวางแผนการออกแบบต้องทำอย่างรัดกุมเพื่อป้องกันข้อผิดพลาดต่างๆ ที่อาจเกิดขึ้น ซึ่งการวางแผนจะต้องครอบคลุมในหลายแง่มุม เช่น บุคคลากร งบประมาณ และการวางแผนด้านโครงสร้างพื้นฐาน ซึ่งการวางแผนที่จะกล่าวถึงในบทความนี้จะเน้นเรื่องการพัฒนา Big Data Platform on Cloud ที่ให้ความสำคัญในการนำข้อมูลมาให้ผู้ใช้งานทั้งนักวิเคราะห์ข้อมูล Business Analysis หรือนักวิทยาศาตร์ข้อมูล Data Science นั้นได้ทำการวิเคราะห์ข้อมูลและนำไปทำ Artificial Intelligent (AI)[16] ด้วยตัวเองหรือที่เรียกว่า Self-service Analytic[17] โดยการวางแผนนี้แบ่งออกเป็น 3 รูปแบบ ดังนี้
1.) การวางแผนการใช้งานบริการที่เกี่ยวกับ Big Data Platform
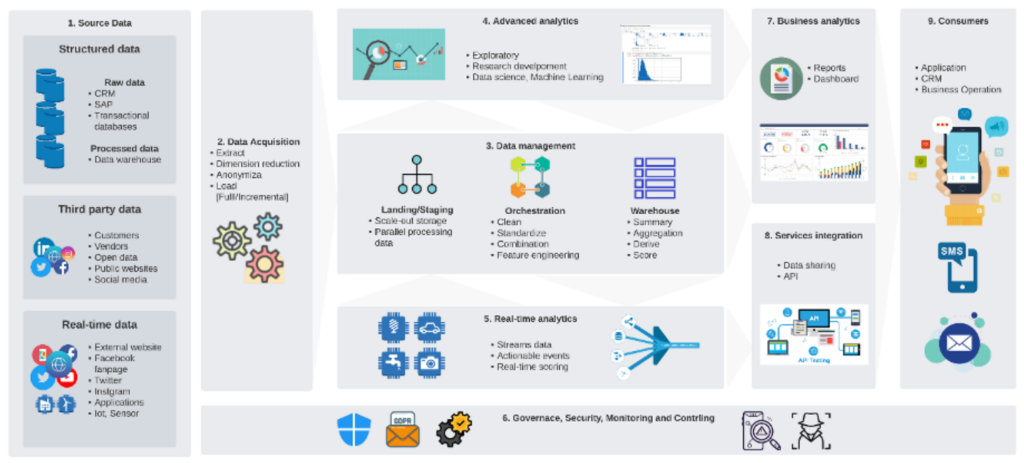
ควรเริ่มจากการตั้งเป้าหมายว่าผลลัพธ์ที่ต้องการคืออะไร จากนั้นจึงออกแบบ Big Data Platform ให้ครอบคลุมกับการใช้งาน ซึ่งส่วนประกอบสำคัญในการทำ Big Data Platform ประกอบไปด้วย 9 ส่วน ดังต่อไปนี้
1. Data Source (ข้อมูลต้นทาง) คือ การกำหนดข้อมูลที่จะเข้าระบบ Big Data Platform โดยข้อมูลสามารถนำเข้าได้หลายรูปแบบ ดังนี้
1.1 ข้อมูล Structure Data ที่อยู่ในรูปแบบของระบบฐานข้อมูลหรือไฟล์ที่มีโครงสร้างข้อมูลชัดเจน
1.2 ข้อมูลภายนอก (Third Party Data) ที่นำเข้าจากระบบอื่นที่เป็นสาธารณะ (Public Platform) ต่างๆ
1.3 ข้อมูลที่อยู่ในรูปแบบของ Real-time ซึ่งอาจจะมีทั้งที่เป็น Structure Data และ Unstructured Data
2. Data Acquisition (นำเข้าข้อมูล) คือ การนำเข้าข้อมูลเข้าสู่ระบบ ซึ่งวิธีการนำข้อมูลเข้านั้นจะเป็นไปตามข้อจำกัดและประเภทของข้อมูลต้นทาง การนำเข้าข้อมูลนั้นจะมีในรูปแบบทั้งการทำ Change Data Capture (CDC)[18] และ Extract Transform Load (ETL)[19] และ API Application[20] รวมไปถึงขั้นตอนนี้จะมีการทำปิดบังข้อมูล (Anonymization[21]) ระหว่างการ Transform หากมีความต้องการปกปิดข้อมูลก่อนนำเข้า Big Data Platform
3. Data Management (บริหารจัดการข้อมูล) จะเป็นการบริหารจัดการข้อมูลที่อยู่บน Platform รวมไปถึงการคัดกรองข้อมูล ทำความสะอาดข้อมูล และรวบรวมข้อมูล ซึ่งจะมีการออกแบบการจัดเก็บข้อมูลเป็น Data Lake และ Data Warehouse หรือ Lakehouse[22]
4. Advance Analytics (วิเคราะห์ข้อมูลเชิงลึก) จะเป็นการนำข้อมูลไปวิเคราะห์เพื่อค้นหารูปแบบของข้อมูล เพื่อนำไปพัฒนาโมเดล Machine Learning ต่าง ๆ
5. Real-time Analytics (วิเคราะห์ข้อมูลแบบเรียลไทม์) จะเป็นการนำข้อมูลแบบ Real-time มาวิเคราะห์ หลังจากนั้นจึงไปจัดเก็บหรือส่งการตอบกลับเพื่อนำข้อมูลไปใช้งานต่อไป
6. Governance, Security, Monitoring and Controlling (บริหารจัดการ Platform) เป็นส่วนประกอบที่สำคัญสำหรับ Big Data Platform ที่มีไว้เพื่อบริหารจัดการโครงสร้างทั้งหมด ทั้งในมุมของการบริหารจัดการผู้ใช้งาน สิทธิ์ผู้ใช้งาน ความปลอดภัย การตรวจสอบการใช้งาน และการป้องกันภัยที่ผิดปกติที่อาจจะเกิดขึ้นบน Big Data Platform
7. Business Analytics (วิเคราะห์ในเชิงของธุรกิจ) จะเป็นส่วนที่เปิดให้ทางผู้ใช้งานสามารถนำข้อมูลไปประกอบการตัดสินใจในเชิงธุรกิจเช่นการทำ Report หรือ Dashboard ต่าง ๆ
8. Services Integration (การแบ่งปันข้อมูลให้กับระบบอื่น) จะเป็นปลายทาง (Endpoint[23]) ที่เปิดให้ผู้ใช้งานหรือ Application เข้าถึงข้อมูลที่จัดเก็บเอาไว้ โดยลักษณะการเข้าถึงในส่วนนี้จะใช้ API เพื่อเข้าถึงหรือเป็นพื้นที่สำหรับการทำ Self-service Analysis
9. Consumers จะเป็นการนำข้อมูลส่งไปถึงลูกค้า (End-user[24]) เช่นการส่งข้อมูลไปยัง Mobile Application และการส่ง Campaign เข้าสู่ช่องทาง SMS หรือ Email
2. การวางแผนด้านบุคลากร
การเตรียมพร้อมบุคลากรต่าง ๆ เช่น ผู้ดูแล ผู้พัฒนาและผู้ใช้งาน ให้มีความรู้ความเข้าใจในการใช้งานเป็นสิ่งที่สำคัญมาก เนื่องจากระบบคลาวน์เป็นสิ่งใหม่และมีวิธีการใช้งานที่แตกต่างกันไปจากของเดิม รวมถึงระบบจะมีการเปลี่ยนแปลงอยู่ตลอด ดังนั้น นอกจากพัฒนาให้บุคลากรมีความรู้ความเข้าใจในเรื่องปัจจุบันแล้ว ยังต้องอัปเดตความรู้ใหม่ๆ อย่างสม่ำเสมอ เพื่อรับมือกับการเปลี่ยนแปลงและการปรับปรุงระบบในอนาคต
3. การวางแผนด้านงบประมาณ
เนื่องจากเป็นการใช้งานในรูปแบบ ‘จ่ายตามจริง’ ดังนั้น การกำหนดการตั้งค่าหลายอย่างจะมีผลต่อค่าใช้จ่าย ผู้ออกแบบสถาปัตยกรรมคลาวน์ จึงจำเป็นต้องเข้าใจทั้งการทำงานของระบบและสามารถประเมินการใช้งานที่จะเกิดขึ้นอย่างแม่นยำ เพื่อวางแผนงบประมาณขั้นต้นที่ต้องใช้ได้อย่างถูกต้องเหมาะสม อย่างไรก็ตาม งบประมาณอาจจะมีการเปลี่ยนแปลงได้ตลอดเวลา ซึ่งต้องทำการประเมินจากจำนวนที่ใช้งานจริงอีกครั้ง และพยายามควบคุมให้อยู่ในงบประมาณที่เหมาะสม เช่น การปรับลดขนาดของเครื่องมือ หรือการวางแผนจองการใช้งานล่วงหน้า 1 หรือ 3 ปี เพื่อลดค่าใช้จ่าย
สำหรับขั้นตอนในการวางแผนการออกแบบนั้น อาจจะต้องใช้เวลาพอสมควร ในการทำความเข้าใจและปรับแผนการใช้งานบริการระบบคลาวน์ รวมถึงแผนบุคลากรและงบประมาณให้เหมาะสมและสามารถทำงานเข้ากับระบบเดิมได้อย่างไร้รอยต่อในกรณีที่มีความจำเป็นต้องใช้งานร่วมกันหรือการเชื่อมต่อกับระบบฐานข้อมูลต้นทาง หลังจากนั้นจึงค่อยเริ่มพัฒนาโดยเริ่มจากการใช้งานหลักก่อน เช่น การนำเข้าข้อมูลและส่วนของการจัดเก็บข้อมูล หรือพัฒนาในรูปแบบของ Proof-of-Concept (PoC)[25] ก่อนแล้วจึงค่อยลงพัฒนาในรูปแบบเต็มไปเรื่อย ๆ ตามส่วนประกอบที่ออกแบบเอาไว้ โดยระหว่างนั้นให้กำหนดผู้ดูแลและผู้พัฒนาในแต่ละส่วน และผู้ใช้งาน พร้อมทั้งการทำฝึกอบรม (Training) ให้สามารถใช้งานระบบใหม่บน Cloud ได้อย่างมีประสิทธิภาพ
หลังจากที่พัฒนาระบบเต็ม และเริ่มมีการทำงานจริงบนระบบแล้ว ควรมีผู้ดูแลคอยสอดส่องการทำงานของระบบอยู่เสมอ เช่น ค่าใช้จ่าย การทำงานของระบบ และทำการปรับปรุง เพื่อให้มั่นใจได้ว่าค่าใช้จ่ายที่เกิดขึ้นนั้นเหมาะสมกับการใช้งาน และสามารถทำงานได้อย่างราบรื่น
5 แนวทางการออกแบบ ‘Cloud Architecture’
สู่ความเป็นเลิศ ในการใช้งาน
หลักการออกแบบ ‘Cloud Architecture’ ควรจะยึดหลัก 5 Pillars[26] เพื่อให้มั่นใจว่าระบบที่ออกแบบนั้นเป็นไปตามแนวทางที่เป็นเลิศ (Best practice) และใช้งานต่อไปได้แบบยั่งยืน พร้อมปรับเปลี่ยนให้เหมาะสมกับการใช้งานอยู่เสมอ ซึ่ง 5 Pillars ประกอบไปด้วย
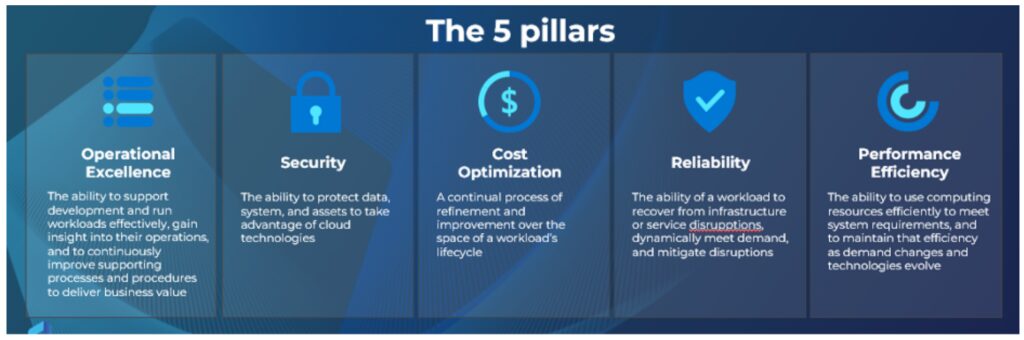
1. หลักการออกแบบด้านการดำเนินงานที่มีประสิทธิภาพ (Operational Excellence)
หลักการออกแบบนี้จะเน้นการออกแบบให้ง่ายต่อการตรวจสอบการพัฒนาของระบบ และสามารถปรับเปลี่ยนได้อยู่ตลอดตามความต้องการของภาคธุรกิจที่อาจจะมีการเปลี่ยนแปลงไปตามสถานการณ์ต่างๆ
2. หลักการออกแบบด้านความปลอดภัย (Security)
การออกแบบด้านความปลอดภัยนั้นจะต้องป้องกันทั้งด้านการแลกเปลี่ยนข้อมูล การเชื่อมต่อ และการจัดเก็บข้อมูล ด้วยการเข้ารหัสไว้ทั้งหมดผ่านกุญแจ (Encryption Key)[27] ที่จัดการได้เองหรือให้ผู้ให้บริการ Cloud บริหารจัดการ ซึ่งจะต้องง่ายต่อการกำหนดสิทธิ์การใช้งานได้ครอบคลุมและเจาะจงมากพอในแต่ละส่วนของการใช้งาน โดยจะต้องสามารถจัดเก็บปูมหลังเหตุการณ์ (System log)[28] การใช้งานและการทำงานต่าง รวมไปถึงระบบจะต้องง่ายต่อการตรวจสอบความปลอดภัย (Security assessment) และสามารถตอบโต้ต่อความผิดปกติได้อัตโนมัติ (Advance threat protection – ATP)[29]
3. หลักการออกแบบด้านค่าใช้จ่ายที่มีประสิทธิภาพ (Cost Optimization)
การออกแบบค่าใช้จ่ายนี้จะมุ่งเน้นไปที่ความสามารถในการตรวจสอบ และคาดเดาค่าใช้จ่ายในอนาคตได้ง่าย สามารถลดค่าใช้จ่ายด้วยกดลดขนาดของเครื่องมือลงตามสัดส่วนที่ไม่จำเป็น
4. หลักการออกแบบด้านความน่าเชื่อถือของระบบ (Reliability)
การออกแบบด้านนี้จะเน้นการออกแบบเพื่อให้ระบบยังคงสามารถทำงานต่อไปได้เหมือนเกิดปัญหาด้วยการทำ Backup and Restore รวมไปถึงการทำสำเนาข้อมูลจัดเก็บเอาไว้หลายแหล่งอย่างปลอดภัย รวมไปถึงรองรับการทำงานเมื่อมีการใช้งานที่มากขึ้นและลดลงเมื่อไม่มีผู้ใช้งาน
5. หลักการออกแบบด้านเสถียรภาพและประสิทธิภาพในการทำงาน (Performance Efficiency)
การออกแบบด้านนี้จะเน้นการออกแบบให้ระบบสามารถทำการพัฒนาและทดสอบได้เหมือนกับการใช้งานจริงบน Production ซึ่งระบบจะต้องรองรับการทำ CI/CD เพื่อลดภาระหน้าที่ซ้ำซ้อนให้กับผู้พัฒนาระหว่างทำการทดสอบและนำระบบไปใช้งานจริงบน Production รวมไปถึงลดความสนใจในเรื่องของเครื่องมือน้อยลงเพื่อนำเวลาไปพัฒนาปรับปรุงระบบได้ดีและเร็วมากขึ้น
ถอดรหัสผลลัทธ์ที่ได้จาก 5 หลักการออกตามแนวทาง
‘Best Practice’ ของ บลูบิค
1. ปรับเปลี่ยนได้ตลอดเวลา (Flexibility to change in anytime)
การใช้งานระบบคลาวน์นั้น ผู้ใช้งานไม่จำเป็นต้องดูแลเครื่องมือการและการติดตั้ง อีกทั้งยังสามารถเลือกใช้ได้ตามความต้องการทั้งเพิ่ม – ลด และสามารถปรับเปลี่ยนได้ตลอดเวลา
2. รองรับความปลอดภัยทุกรูปแบบ (All included Security solution)
ความปลอดภัยบน Cloud นั้นมีพื้นฐานไม่ต่างจากระบบ On-premise ทั้งระบบ ซึ่งบางผู้ให้บริการคลาวน์มี Solutions ด้านความปลอดภัยอย่างครบถ้วน โดยไม่จำเป็นต้องไปใช้งานร่วมกับระบบอื่น และยังครอบคลุมถึง Server บน On-premise อีกด้วย
3. พัฒนาระบบเร็วขึ้น (Shorter go to market time)
เนื่องจากการเลือกใช้งานมีขั้นตอนที่ไม่ยุ่งยากและติดตั้งง่าย ทำให้มีเวลาในการพัฒนาโปรแกรมที่สามารถตอบโจทย์ความต้องการของภาคธุรกิจมากขึ้น ดังนั้น ระบบที่ผ่านการออกแบบ ‘Cloud Architecture’ จึงมีประสิทธิภาพเพิ่มขึ้น เมื่อเวลาระบบเกิดปัญหาสามารถกู้คืนระบบได้อัตโนมัติรวดเร็ว หรือใช้วิธีการย้ายส่วนที่เกิดปัญหาไปใช้งานใน Region อื่นเป็นการชั่วคราวได้ในทันที
4. พัฒนาด้วยระบบของจริง (Develop like a Production)
ด้วยระบบที่สามารถพัฒนาบนโครงสร้างที่เหมือนกับการใช้จริงบน Production ทำให้การทดลองสิ่งใหม่ทำได้อย่างง่ายดายและตรวจสอบผลกระทบได้ก่อนที่จะนำระบบไปใช้งานจริง รวมไปถึงการใช้งานร่วมกับระบบอื่น ๆ ทั้งระบบเดิม ระบบของผู้ให้บริการ Cloud เจ้าอื่น และโปรแกรมต่าง ๆ ได้อย่างมีประสิทธิภาพ
5. เลิกจ่ายล่วงหน้าราคาแพง (Convert CAPEX[30] to OPEX[31])
เปลี่ยนการจ่ายเงินมหาศาลล่วงหน้ามาเป็นค่าใช้จ่ายรายเดือน หรือรายปีสำหรับบางรายการ และสามารถลดขนาดการใช้งานลงในช่วงเวลาที่ไม่จำเป็น เพื่อลดภาระค่าใช้จ่ายที่ไม่จำเป็นลง และทำให้การบริหารจัดการงบประมาณด้านไอทีมีประสิทธิภาพมากขึ้น
สิ่งสำคัญที่นักออกแบบ ‘Cloud Architecture’ ต้องใส่ใจ
1. เนื่องจากค่าใช้จ่ายเป็นไปตามการใช้งาน ดังนั้น การคิดคำนวณการใช้งานต้องทำอย่างรอบคอบ เช่น เครื่องมือที่ใช้ในการคำนวณ จำนวนข้อมูลที่ประมวลผล การส่งข้อมูลไปยังที่ต่าง ๆ จำนวนการเรียกใช้งาน เพื่อให้สามารถคาดการณ์การใช้งานที่ใกล้เคียงกับของจริงมากที่สุด
2. เนื่องจากระบบสามารถเพิ่ม-ลดได้ตลอดเวลา ดังนั้น การควบคุมงบประมาณนั้นต้องดูแลอย่างใกล้ชิด เพื่อให้มั่นใจว่างบประมาณไม่บานปลายและไม่ได้จ่ายเกินความจำเป็น
3. เนื่องจากการตั้งค่าสามารถทำได้ง่าย จึงทำให้ถูกเข้าถึงจากผู้ไม่พึงประสงค์ได้ จึงจำเป็นต้องมีการตรวจสอบอยู่เสมอเพื่อป้องกันการตั้งค่าที่ผิดพลาด และการกำหนดสิทธิ์ที่มากเกินไปความจำเป็นสำหรับการใช้งาน
4. โดยส่วนมากการใช้ Application หรือ Platform ของผู้ให้บริการนั้น ๆ แล้ว จะติดปัญหาในเรื่องของ Vendor lock in[32] ทำให้ยากต่อการย้ายหรือเปลี่ยนผู้ให้บริการ เว้นแต่จะใช้ Solution ที่มีพื้นฐานมาจาก Open Source หรืออยู่ในรูปแบบของ Standard Language
5. การเลือกบุคลากรที่พร้อมสำหรับการกำกับดูแลระบบ และการพัฒนาบุคลากรที่มีให้เข้าใจในทุกส่วนนั้นต้องใช้เวลา เนื่องจากทั้งระบบทำงานเชื่อมต่อกันเป็นผืนใหญ่ ซึ่งระบบจะมีการเปลี่ยนแปลงและมีสิ่งใหม่เข้ามาอยู่ตลอดเวลา ทำให้ผู้ดูแลระบบควรมีความรู้และความเข้าใจและต้องติดตามการเปลี่ยนแปลงของเทคโนโลยีใหม่อยู่เสมอ
6. เนื่องจากระบบไม่ได้แยกการทำงานเป็นชุด ๆ เหมือนกับ On-premises และการใช้งานระบบคลาวน์ มีหลักการคิดค่าใช้จ่ายหลายแง่มุม ดังนั้น การทำแยกค่าใช้จ่ายจากภาพรวมกลับไปยังหน่วยงานหรือทีมงานที่ใช้งานแต่ละส่วนนั้นจำเป็นต้องมีการวางแผนการกำหนด Tag ที่มีการกำหนดเป็นมาตรฐาน (Tagging standard) รวมไปถึงการดำเนินการตรวจสอบและทำการแยกค่าใช้งานที่เกิดขึ้นที่ชัดเจน
[1] https://en.wikipedia.org/wiki/On-premises_software
[2] https://en.wikipedia.org/wiki/Command-line_interface
[3] https://docs.microsoft.com/en-us/azure/compliance/
[4] https://aws.amazon.com/compliance/
[5] https://www.todayilearnedcloud.com/What-Does-On-Demand-Pricing-Mean-For-The-Cloud/
[6] https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-iaas/
[7] https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-paas/
[8] https://www.ibm.com/th-en/topics/mapreduce
[9] https://www.docker.com/resources/what-container/
[10] https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-saas/
[11] https://www.cloudflare.com/learning/serverless/what-is-serverless/
[12] https://docs.microsoft.com/en-us/azure/availability-zones/az-overview
[13] https://www.techtarget.com/searchdatacenter/definition/high-availability
[14] https://www.techtarget.com/searchdisasterrecovery/definition/fault-tolerant
[15] https://aws.amazon.com/blogs/architecture/disaster-recovery-dr-architecture-on-aws-part-i-strategies-for-recovery-in-the-cloud/
[16] https://en.wikipedia.org/wiki/Artificial_intelligence
[17] https://www.gartner.com/en/information-technology/glossary/self-service-analytics
[18] https://www.qlik.com/us/change-data-capture/cdc-change-data-capture
[19] https://www.ibm.com/cloud/learn/etl
[20] https://www.mulesoft.com/resources/api/what-is-an-api
[21] https://www.imperva.com/learn/data-security/anonymization/
[22] https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
[23] https://www.paloaltonetworks.com/cyberpedia/what-is-an-endpoint
[24] https://www.techtarget.com/whatis/definition/end-user
[25] https://www.techtarget.com/searchcio/definition/proof-of-concept-POC
[26] https://docs.aws.amazon.com/wellarchitected/latest/high-performance-computing-lens/the-five-pillars-of-the-well-architected-framework.html
[27] https://en.wikipedia.org/wiki/Key_(cryptography)
[28] https://en.wikipedia.org/wiki/Logging_(software)
[29] https://digitalguardian.com/blog/what-advanced-threat-protection-atp
[30] https://www.techtarget.com/whatis/definition/CAPEX-capital-expenditure
[31] https://www.techtarget.com/whatis/definition/OPEX-operational-expenditure
[32] https://www.techtarget.com/searchdatacenter/definition/vendor-lock-in


