



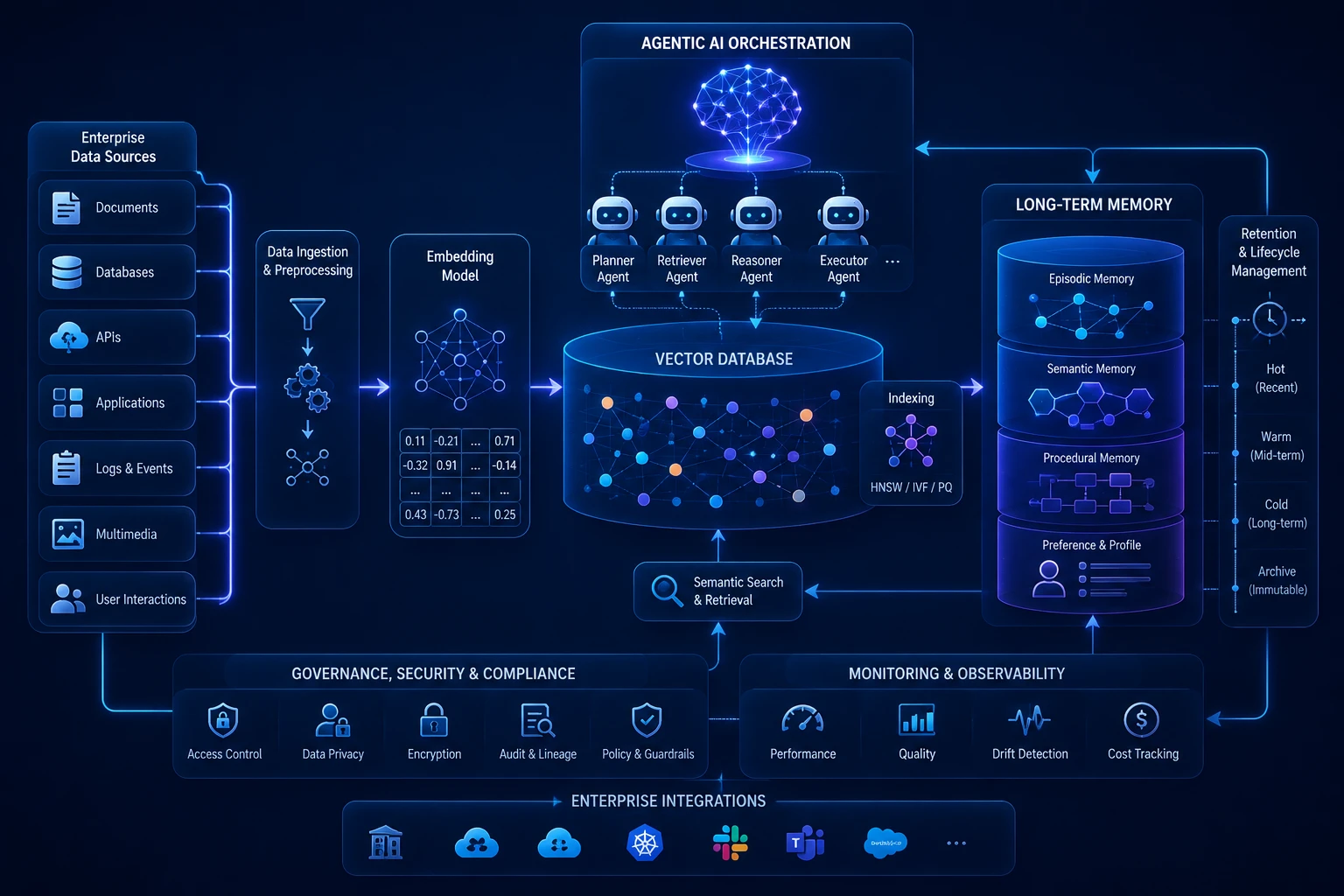
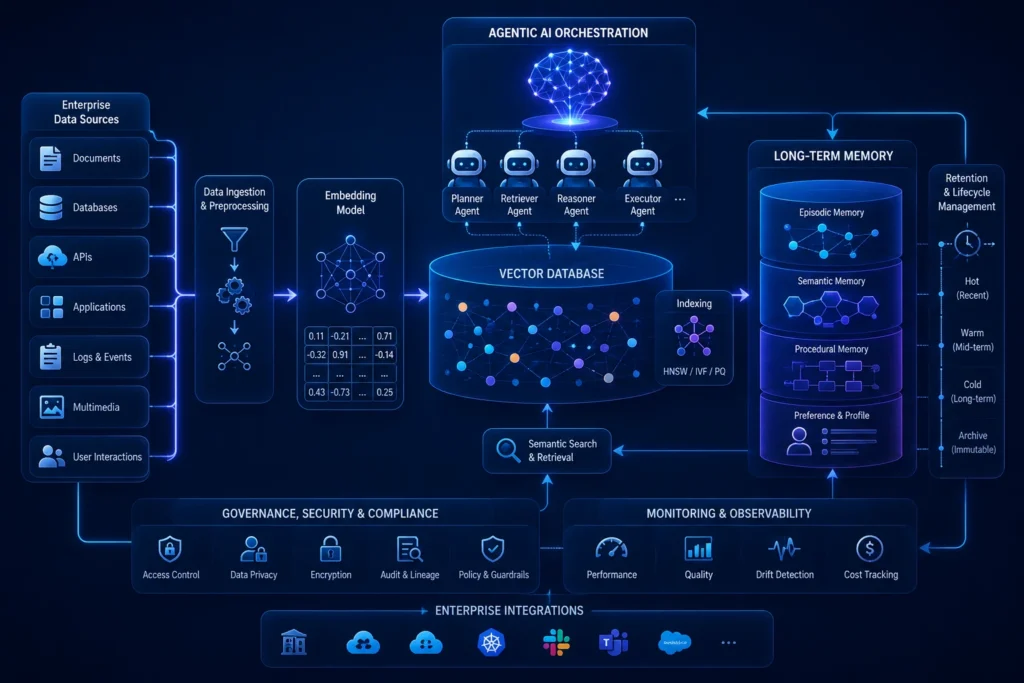
การออกแบบ Vector Database และ Long-term Memory สำหรับ Agentic AI ขนาดใหญ่ในระดับ Enterprise
หากโมเดลภาษาขนาดใหญ่ (LLM) เปรียบเสมือนแกนประมวลผลของ Agentic AI ระบบความจำระยะยาว หรือ Long-term Memory ก็เปรียบเสมือนชั้นความจำที่ช่วยบันทึก เรียกคืน และจัดระเบียบองค์ความรู้ บริบท และประสบการณ์ที่เกี่ยวข้องกับการทำงานขององค์กร การที่เอเจนท์อัจฉริยะจะสามารถทำงานที่มีความซับซ้อนหรือทำงานต่อเนื่องหลายขั้นตอนได้อย่างมีประสิทธิภาพนั้น ไม่ควรพึ่งพาเพียงความจำระยะสั้นใน Context Window เพียงอย่างเดียว วิศวกรไอทีในระดับ Enterprise จึงจำเป็นต้องออกแบบโครงสร้างข้อมูลและเลือกใช้ Vector Database อย่างเหมาะสม เพื่อให้ AI ค้นคืนข้อมูลที่เกี่ยวข้องมาใช้ประกอบการตัดสินใจได้รวดเร็วขึ้น แม่นยำขึ้น และลดการใช้ Context หรือ Token ที่ไม่จำเป็น
ทำไม Agentic AI ในระดับองค์กรต้องมี Long-term Memory?
เมื่อเรานำเอเจนท์ไปรันงานในระบบขนาดใหญ่ (Enterprise Workflows) เอเจนท์จะต้องเผชิญกับข้อจำกัด 2 ประการหลัก คือ ความจุของหน่วยความจำปัจจุบัน และการลืมบริบทเก่าเมื่อบทสนทนายาวขึ้น ระบบ Long-term Memory จึงเข้ามาแก้ปัญหานี้โดยแบ่งหน้าที่เป็น 2 ส่วนหลัก
- Semantic Memory (ความจำด้านองค์ความรู้): การจัดเก็บข้อมูลภายในบริษัท นโยบาย คู่มือสินค้า หรือฐานข้อมูลดิบ ผ่านกระบวนการ RAG (Retrieval-Augmented Generation) เพื่อให้ AI ใช้เป็นฐานข้อมูลอ้างอิงความจริง
- Episodic Memory (ความจำด้านประสบการณ์): การบันทึก “ประวัติการทำงานและผลลัพธ์ในอดีต” ของตัวเอเจนท์เอง เช่น คราวที่แล้วเอเจนท์เคยใช้เครื่องมือนี้แก้ปัญหารูปแบบนี้สำเร็จอย่างไร เพื่อให้นำมาประยุกต์ใช้ซ้ำในปัจจุบันผ่านกลไก Reflection และ Self-Correction
กลยุทธ์การเลือก Vector Database สำหรับระบบ Agentic AI
Vector Database ทำหน้าที่เป็นผู้เก็บและค้นหาพิกัดข้อมูล (Embeddings) ที่ AI เข้าใจ เพื่อช่วยให้ระบบค้นหาข้อมูลจากความใกล้เคียงเชิงความหมายได้ การเลือกใช้ในระดับ Enterprise ควรพิจารณาทั้งประสิทธิภาพ ความปลอดภัย การกำกับดูแลข้อมูล การเชื่อมต่อกับระบบเดิม และรูปแบบการค้นคืนที่เหมาะกับ use case
- Pinecone / Milvus / Qdrant: เหมาะสำหรับองค์กรที่ต้องการระบบ Vector Database แท้ๆ (Native Vector DB) ที่รองรับการสืบค้นข้อมูลมหาศาลในระดับมิลลิวินาที มีความยืดหยุ่นสูง และรองรับรูปแบบการค้นหาเชิงเวกเตอร์หรือ Hybrid Search ได้ดี ทั้งนี้ ความเร็วและความสามารถในการอัปเดตข้อมูลแบบใกล้ Real-time จะขึ้นอยู่กับสถาปัตยกรรม ขนาดข้อมูล และการตั้งค่าระบบ
- pgvector (PostgreSQL) / MongoDB Atlas: เหมาะสำหรับองค์กรที่ต้องการผสานข้อมูลเวกเตอร์เข้ากับฐานข้อมูลเดิมที่มีอยู่ (Hybrid Data) หรือมีความต้องการใช้ข้อมูลเวกเตอร์ร่วมกับข้อมูลเชิงโครงสร้าง เพื่อความง่ายในการดูแลรักษาโครงสร้างระบบไอทีเดิม
- Hybrid Search Capabilities: ในหลาย use case ระดับองค์กร ควรพิจารณา Vector Database ที่เลือกต้องรองรับการค้นหาแบบผสมผสาน ทั้งการค้นหาจากความหมาย (Dense Vector) และการค้นหาจากคีย์เวิร์ดตรงๆ (Sparse Vector/BM25) เพื่อเพิ่มคุณภาพของการดึงข้อมูล โดยเฉพาะกรณีที่ต้องค้นทั้งความหมายกว้างและคำเฉพาะทางในเอกสาร
แนวทางการออกแบบสถาปัตยกรรมหน่วยความจำที่ยืดหยุ่น
ในการพัฒนาสถาปัตยกรรม Agentic AI ร่วมกับ Agentic AI Framework ยอดนิยม ควรวางระบบหน่วยความจำให้ครอบคลุม ทั้งการนำเข้าข้อมูล การค้นคืน การควบคุมสิทธิ์ และวงจรชีวิตของข้อมูลตามโครงสร้างนี้
- Data Chunking & Metadata Tagging: การแบ่งย่อยเนื้อหาเอกสารให้มีขนาดเหมาะสมกับลักษณะข้อมูลและโมเดลที่ใช้ (Chunking) พร้อมติดป้ายกำกับ (Metadata) เช่น แผนก วันที่ ประเภทเอกสาร เวอร์ชัน หรือสิทธิ์การเข้าถึง เพื่อช่วยให้ AI ค้นพบข้อมูลที่เกี่ยวข้องและลดความเสี่ยงจากการดึงบริบทผิดชุด
- Memory Eviction Policies: การกำหนดสิทธิ์และระยะเวลาในการลบหรือจัดเก็บข้อมูลความจำเก่าที่ไม่จำเป็น เพื่อป้องกันไม่ให้ฐานข้อมูลบวมและกินทรัพยากรมากเกินไป
- Data Security & Isolation: วางระบบควบคุมการเข้าถึงข้อมูล (Access Control) การแยกสิทธิ์ตามผู้ใช้ ทีม และการทำ audit trail เพื่อให้มั่นใจว่าเอเจนท์ของพนักงานแต่ละคนจะค้นคืนข้อมูลจาก Vector Database ได้เฉพาะส่วนที่ตนเองมีสิทธิ์ใช้งานเท่านั้น
สรุป: โครงสร้างข้อมูลที่แข็งแกร่งคือรากฐานของ AI ที่ฉลาด
ความสามารถของ Agentic AI ระดับ Enterprise ไม่ได้วัดจากการใช้โมเดลที่แพงที่สุดเพียงอย่างเดียว แต่วัดจากคุณภาพของข้อมูล สถาปัตยกรรมความจำ และกระบวนการค้นคืนข้อมูลที่ออกแบบมาอย่างเหมาะสม องค์กรที่วางสถาปัตยกรรม Long-term Memory และเลือกใช้ Vector Database ได้สอดคล้องกับโจทย์ธุรกิจ จะมีโอกาสสร้างระบบ AI ที่ทำงานได้แม่นยำ ปลอดภัย และต่อยอดได้ในระยะยาวมากขึ้น
วางรากฐาน Data & AI Infrastructure ระดับโลกกับ Bluebik Group
การทำ Data Grounding และจัดโครงสร้าง Vector Database ให้เสถียรและปลอดภัยในระดับ Enterprise เป็นงานที่มีความซับซ้อนสูงและต้องการสถาปนิกข้อมูลผู้เชี่ยวชาญ Bluebik Group พร้อมช่วยเหลือองค์กรของคุณในการออกแบบสถาปัตยกรรมหน่วยความจำและระบบข้อมูลสำหรับ Agentic AI ครบวงจร เราช่วยคุณจัดการตั้งแต่การจัดการข้อมูลขนาดใหญ่ (Big Data Architecture) การเลือกเครื่องมือที่เหมาะกับบริบทธุรกิจ ไปจนถึงระบบรักษาความปลอดภัยของข้อมูลตามมาตรฐานสากล สนใจเปลี่ยนข้อมูลองค์กรให้เป็นพลังขับเคลื่อน AI อัจฉริยะ ติดต่อ Bluebik วันนี้
ติดตามทุกเทรนด์ธุรกิจและนวัตกรรมเทคโนโลยีไปกับเรา
![]()
![]()
![]()
![]()
![]()
Source:
- LangChain – Long-term Memory for Agents
- Pinecone – Vector Databases & RAG
- LlamaIndex Documentation
- Qdrant Documentation
- Milvus Documentation
- pgvector Documentation
- Reflexion Paper (episodic memory / self-correction)


