ในบรรดา subfields ของ machine learning ณ ตอนนี้คงไม่มีอะไรที่กำลังเป็นกระแสมากไปกว่า reinforce-ment learning อีกแล้ว (ต่อไปจะขอเรียกย่อว่า RL) ซึ่งถ้าเราย้อนกลับไปซัก 2-3 ปีที่แล้ว ตำแหน่งนี้ยังคงเป็นของ deep learning อยู่เลย ชัดเจนว่าโลกเปลี่ยนเร็วแค่ไหนกัน
บทความนี้ตั้งใจเล่าแบบง่ายๆให้คนที่พอมีพื้นเกี่ยวกับ machine learning มาบ้าง ได้เข้าใจว่า RL คืออะไร แล้ว fit in อยู่ตรงไหนใน field ของวิชานี้
Supervised, Unsupervised and RL
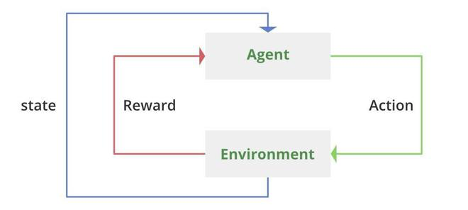
คงไม่ขอ deep dive มากใน 2 อันแรก Supervised คือ เรารู้ค่าของ output variables ส่วนถ้าเป็น Un-supervised คือ เราไม่รู้ ในขณะที่ RL นั้น บางตำรากล่าวว่าเป็นลูกผสมระหว่าง Supervised กับ Unsupervised แต่ในมุมมองส่วนตัวแล้ว RL เป็นอีก learning paradigm ที่อยู่คนละ setting กับสองอันแรกโดยสิ้นเชิง เพราะใน 2 แบบแรกตัว model อย่างน้อยต้องผ่านการ training ก่อนที่จะนำไป implement ใน real environment (ขอเรียกย่อว่า env) ในขณะที่ RL คือตัว model เรียนรู้ใน env เลย โดยที่ agent (ตัว model) ใส่ action (input) เข้าไปใน env (function ที่ map ระหว่าง input กับ output) และ env ก็จะส่ง reward + state (outputs) กลับออกมา โดยทั้งหมดนี้อยู่บนพื้นฐานของ probabilistic model ชื่อ sequential decision process ข้อสังเกตคือ แม้ว่า outputs ของ RL จะมี 2 อันคือ reward กับ state ของ env แต่เป้าหมาย (objective function) ของ RL คือการ maximize reward ที่จะได้รับจาก env เท่านั้น โดยที่ state เป็นแค่ learning co-factor เท่านั้น ซึ่งต่างจาก traditional learning (Supervised & Unsupervised) ที่มักจะเอา outputs ทั้งหมดมาสร้างเป็น objective function
นอกจากเรื่อง training แล้ว RL ยังต่างจาก traditional learning อย่างน้อยอีก 2 จุดใหญ่ๆ 1) ในขณะที่ traditional learning นั้น assume ว่า input ไม่ได้เปลี่ยน state ของ function ที่ map ระหว่าง input กับ output แต่ RL นั้นอาจจะเปลี่ยนหรือไม่เปลี่ยน state ของ env ก็ได้ 2) ใน traditional learning เมื่อเราใส่ input เราแทบจะรู้ output ในทันที แต่ใน RL หลายๆครั้งเราจะไม่รู้ output ทันที ตัวอย่างที่สุดโต่ง เช่น การเล่นเกมที่จะรู้ว่า reward ชนะหรือ regret แพ้จริงๆก็ต่อเมื่อเกม (learning) นั้นจบแล้วเท่านั้น ยังมีความแตกต่างระหว่าง traditional learning กับ RL อยู่อีกหลายข้อ บทความนี้คงไม่ลงลึกมากกว่านี้ แค่อยากจะเน้นย้ำเฉยๆว่า RL เป็นคนละ learning paradigm กับ traditional learning models แค่นั้น
Deep Learning + RL = ขอเล่นใหม่ของ DS geeks
แกนหลักของ deep learning คือ Neural Network ซึ่งเป็น ML Model ถูกคิดค้นมาตั้งแต่ยุค 60 แต่กลับมาเกิดใหม่เป็นกระแสในยุคที่คอมพิวเตอร์มีความสามารถที่จะรองรับการคำนวณ Big Data ได้แล้วนั่นเอง
Deep RL คือการเอาเทคนิคของ deep learning มาประยุกต์ใช้ใน RL กล่าวง่ายๆคือ เอา Neural Network มาเป็นเครื่องมือในการ approximate functions และ policies ใน RL นั้นเอง ซึ่งในบทความนี้ เราจะมาอธิบาย basics ของ deep RL ผ่านโปรแกรม simulation เพื่อดู algorithms ที่ใช้ในการแก้ปัญหา โดยจะเขียนโปรแกรมในภาษา Julia บน Pluto notebook
Swinging Pendulum (ลูกตุ้มแกว่ง)
โจทย์ Swinging Pendulum เป็นโจทย์ตัวอย่างที่คนลงวิชา RL ต้องได้เจอทุกคน เป็นปัญหาในกลุ่ม Markov decision process (MDP) แบบ fully observable state กล่าวคือเรารู้ความเป็นไปของ env state ทั้งหมด โจทย์คือเราต้องพยายามใส่ torque เข้าไปให้เหมาะสม จนกระทั่งสามารถ balance ลูกตุ้มให้ตั้งฉาก 90 องศาอยู่ด้านบนได้
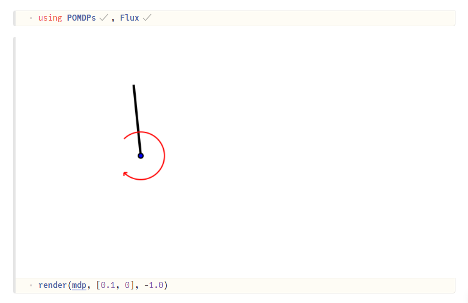
ในขั้นตอนถัดไป เราต้องกำหนด state space (แทนด้วย δ) ของโจทย์ ซึ่งในกรณีลูกตุ้มแกว่งจะเป็นมุมองศาของลูกตุ้ม θ กับความเร็วเชิงมุม ω ซึ่งก็คือ
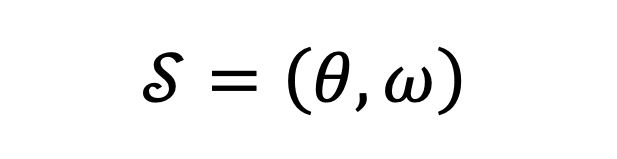
โดยทั้ง θ กับ ω เป็นตัวแปรสุ่มกระจายตัวแบบ Gaussian โดยมีค่า mean เป็น 0 และค่าความเบี่ยงเบนเป็น (เขียนสัญลักษณ์ย่อเป็น ~N(0,1))

เมื่อมี state space แล้ว เราต้องกำหนด action space (แทนด้วย A) ซึ่งก็คือเซตของวิธีการใส่ torque ให้กับลูกตุ้ม ใส่แบบทวนเข็ม ตามเข็ม ใส่กี่ Newton-Meter ซึ่งในโจทย์ RL นั้นจะแบ่งออกเป็น 2 กลุ่มใหญ่ๆ คือ โจทย์ที่ action space เป็น discrete กับ continuous ซึ่ง algorithms ที่ใช้ในการแก้ปัญหาทั้ง 2 แบบก็จะแตกต่างกัน ในบทความนี้จะยกตัวอย่าง 2 กระบวนการวิธีการโจทย์ RL 1) Q-Learning 2) Actor-Critic Method โดยเราจะใช้ Julia package ชื่อ Crux ในการทำ simulation ให้ง่ายขึ้น

Deep Q-Learning
ในบรรดา RL algorithms แล้วทั้งหมด Q-Learning หรือ Value Learning ถือว่าเป็นวิธีการที่พื้นฐานที่สุดและยังเป็นวิธีการที่ mathematical formula มีความ elegant ที่สุดวิธีนึง (ซึ่งอะไรที่มัน mathematically elegant เนี้ยมักจะใช้กับโจทย์ตุ๊กตาเป็นหลัก เอามาใช้จริงมักจะไม่ค่อยมีประสิทธิภาพมากนัก) โดยเราจะหา optimal policy จากการเลือก action ที่ maximize ตัว Q function (เป็น function ของ reward) ซึ่งชัดเจนว่า action space ในกรณีนี้จะต้อง finite หรือ discrete นั้นเอง โดย algorithm ที่เราจะใช้ในการแก้ปัญหาเคสนี้คือ deep q-network (DQN) ในการเลือก optimal policy
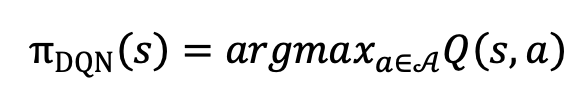
จาก discrete action space A
โดย neural network ที่จะใช้ในการเลือก πDQN(s) จาก A จะเป็น 3-layer discrete network (ขอเรียกว่า q-network)
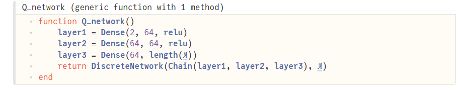
เมื่อได้ q-network แล้ว เราจึงสร้าง DQN solver

เพื่อแก้หา optimal policy ได้


Actor-Critic Method
ถ้า q-learning เป็นวิธีการที่อยู่ในฝั่งค่อนไปทางพื้นทาง Actor-Critic (A2C) ก็ถือเป็นวิธีการที่ค่อนข้าง advanced สามารถรองรับโจทย์ที่มีความซับซ้อนมากขึ้น โดย A2C ใช้ surrogate ของ q-function (Critic) มาช่วยในการ optimize ตัว policy (Actor) โดยตรง
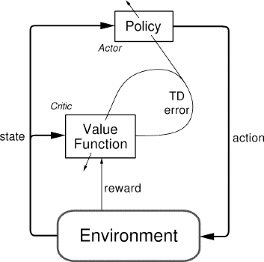
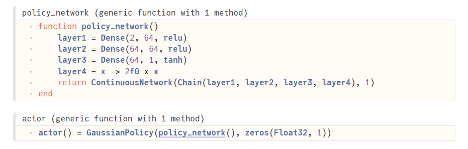
ข้อได้เปรียบที่ A2C มีเหนือกว่า Q-Learning อย่างชัดเจนคือมันสามารถรับมือกับ continuous action space ได้ โดยเราจะให้ action กระจายตัวแบบ Gaussian และ Actor follows Gaussian policy ซึ่งเราจะใช้เทคนิคของ deep learning ในทำนองเดียวกับ q-network โดยเราจะเลือก mean ของ Gaussian policy โดยใช้ neural network (ขอเรียกว่า policy network)
และในส่วนของ Critic นั้นคือ surrogate function ของ q function เรียกว่า advantage A(s,a) นิยามโดย
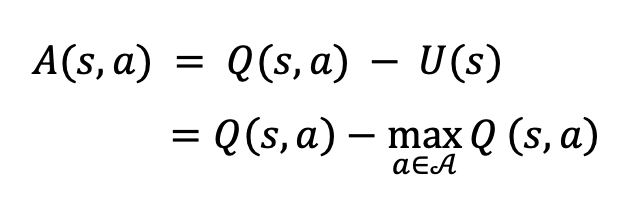
ซึ่งเราจะใช้ neural network เป็น function approximator ของ A(s,a) โดยตรง
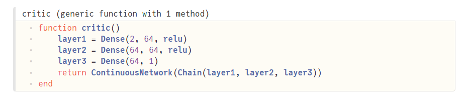
เมื่อได้ทั้ง Actor และ Critic แล้ว เราก็สามารถกำหนด policy ได้

ในเคสนี้ เราจะใช้ algorithm ที่ชื่อว่า Proximal Policy Optimization (PPO) ซึ่งเป็น policy-based RL algorithm สำหรับ deep learning โดยเฉพาะ

เพื่อแก้หา optimal policy ออกมาได้

ด้วยความที่โจทย์ลูกตุ้มเป็นโจทย์ basic เราจึงอาจไม่เห็นความต่างของวิธีการทั้งสองมาก แต่แน่นอนว่าในโจทย์ที่มีความซับซ้อนมากขึ้น policy ต้องมีความแม่นยำในการกำหนด action ให้ได้ระดับทศนิยมหลายตำแหน่งนั้น การเลือกใช้ algorithms ให้เหมาะสมจึงเป็นสิ่งสำคัญมาก
สำหรับบทความนี้ก็จบลงเพียงเท่านี้ อาจจะมีเนื้อหาบางอย่างที่ยังอธิบายงงๆบ้างก็ขอประทานโทษล่วงหน้านะครับ อย่างน้อยคิดว่าเป็นการแลกเปลี่ยนกับผู้อ่านและแบ่งปันมุมมองที่ได้ตกผลึกมาซึ่งสามารถไปจุดประกายความคิดบางอย่างเพิ่มเติมได้ ก็ถือว่าบทความนี้ได้ทำหน้าที่ของมันแล้วละครับ ต้องขอขอบคุณท่านผู้อ่านทุกท่านที่สละเวลาอ่านมาจนจบด้วยครับผม






